搜索到
2
篇与
DeepSeek
的结果
-
 英语时文《2025年春节系列阅读》 免费下载 2025年春节时文阅读,汇集了多个热门话题,包括哪吒、王菲、李子柒、机器人秧歌、Deepseek等,每个话题都超火。这些时文不仅内容丰富,还涵盖了多种文体,适合英语学习者提升阅读能力和了解最新文化动态。100%原创内容,让你在春节期间也能充实自己。-电子书-智汇资源库-zhzyk-vip时文简介《2025年春节系列阅读》是一本聚集了多个热门话题的英语时文读物,适合英语学习者在春节期间提升阅读能力和了解最新文化动态。本书包含了丰富的文章,涉及了多个领域的热门话题,如哪吒、王菲、李子柒、机器人秧歌、Deepseek等。每个话题都备受关注,内容有趣且具有很高的可读性。时文内容哪吒:介绍了哪吒这一文化符号在当代的演变和发展,从电影《哪吒之魔童降世》的爆红到哪吒在现代文化中的新形象,探讨了传统文化与现代文化的融合。王菲:分析了王菲作为华语乐坛的代表性人物,她的音乐风格和影响力,以及她在音乐界的地位和贡献。李子柒:讲述了李子柒通过短视频平台传播中国传统文化的故事,她的视频不仅在国内受到广泛关注,在海外也赢得了大量粉丝。机器人秧歌:介绍了机器人技术在传统艺术中的应用,机器人秧歌的出现不仅增添了节日的喜庆氛围,也展现了科技与文化的结合。Deepseek:探讨了Deepseek这一新兴科技公司的发展动态,包括其在人工智能和大数据领域的最新进展和应用场景。时文特点内容丰富:涵盖了多个领域的热门话题,既有传统文化的传承,也有现代科技的应用,内容丰富多样。文体多样:包括新闻报道、评论文章、人物专访等多种文体,适合不同阅读兴趣的读者。语言地道:文章语言地道,适合英语学习者提升阅读能力和词汇量。最新动态:收录了2025年春节期间的最新时文,帮助读者了解最新的文化动态和技术进展。适合对象《2025年春节系列阅读》适合以下人群:英语学习者:希望提升英语阅读能力的学习者,这些时文内容丰富,语言地道,适合不同水平的读者。文化爱好者:对传统文化和现代文化感兴趣的读者,这些时文涵盖了多个热门话题,内容有趣且具有很高的可读性。科技爱好者:对新兴科技感兴趣的读者,特别是对人工智能和大数据领域感兴趣的读者。节日阅读者:希望在春节期间充实自己的读者,这些时文不仅内容丰富,还具有很高的阅读价值。高速下载,轻松获取为了让所有爱好者都能方便地获取这一珍贵资源,我们特别提供《2025年春节系列阅读》的下载链接。夸克网盘的高速下载,确保你能够快速获取这一资源,不再错过任何一个宝贵的阅读机会。无论是在家中休息,还是在旅途中,都能随时随地享受高质量的阅读体验。{anote icon="fa-download" href="https://pan.quark.cn/s/afacd590e1fc" type="error" content="点此下载"/}
英语时文《2025年春节系列阅读》 免费下载 2025年春节时文阅读,汇集了多个热门话题,包括哪吒、王菲、李子柒、机器人秧歌、Deepseek等,每个话题都超火。这些时文不仅内容丰富,还涵盖了多种文体,适合英语学习者提升阅读能力和了解最新文化动态。100%原创内容,让你在春节期间也能充实自己。-电子书-智汇资源库-zhzyk-vip时文简介《2025年春节系列阅读》是一本聚集了多个热门话题的英语时文读物,适合英语学习者在春节期间提升阅读能力和了解最新文化动态。本书包含了丰富的文章,涉及了多个领域的热门话题,如哪吒、王菲、李子柒、机器人秧歌、Deepseek等。每个话题都备受关注,内容有趣且具有很高的可读性。时文内容哪吒:介绍了哪吒这一文化符号在当代的演变和发展,从电影《哪吒之魔童降世》的爆红到哪吒在现代文化中的新形象,探讨了传统文化与现代文化的融合。王菲:分析了王菲作为华语乐坛的代表性人物,她的音乐风格和影响力,以及她在音乐界的地位和贡献。李子柒:讲述了李子柒通过短视频平台传播中国传统文化的故事,她的视频不仅在国内受到广泛关注,在海外也赢得了大量粉丝。机器人秧歌:介绍了机器人技术在传统艺术中的应用,机器人秧歌的出现不仅增添了节日的喜庆氛围,也展现了科技与文化的结合。Deepseek:探讨了Deepseek这一新兴科技公司的发展动态,包括其在人工智能和大数据领域的最新进展和应用场景。时文特点内容丰富:涵盖了多个领域的热门话题,既有传统文化的传承,也有现代科技的应用,内容丰富多样。文体多样:包括新闻报道、评论文章、人物专访等多种文体,适合不同阅读兴趣的读者。语言地道:文章语言地道,适合英语学习者提升阅读能力和词汇量。最新动态:收录了2025年春节期间的最新时文,帮助读者了解最新的文化动态和技术进展。适合对象《2025年春节系列阅读》适合以下人群:英语学习者:希望提升英语阅读能力的学习者,这些时文内容丰富,语言地道,适合不同水平的读者。文化爱好者:对传统文化和现代文化感兴趣的读者,这些时文涵盖了多个热门话题,内容有趣且具有很高的可读性。科技爱好者:对新兴科技感兴趣的读者,特别是对人工智能和大数据领域感兴趣的读者。节日阅读者:希望在春节期间充实自己的读者,这些时文不仅内容丰富,还具有很高的阅读价值。高速下载,轻松获取为了让所有爱好者都能方便地获取这一珍贵资源,我们特别提供《2025年春节系列阅读》的下载链接。夸克网盘的高速下载,确保你能够快速获取这一资源,不再错过任何一个宝贵的阅读机会。无论是在家中休息,还是在旅途中,都能随时随地享受高质量的阅读体验。{anote icon="fa-download" href="https://pan.quark.cn/s/afacd590e1fc" type="error" content="点此下载"/} -
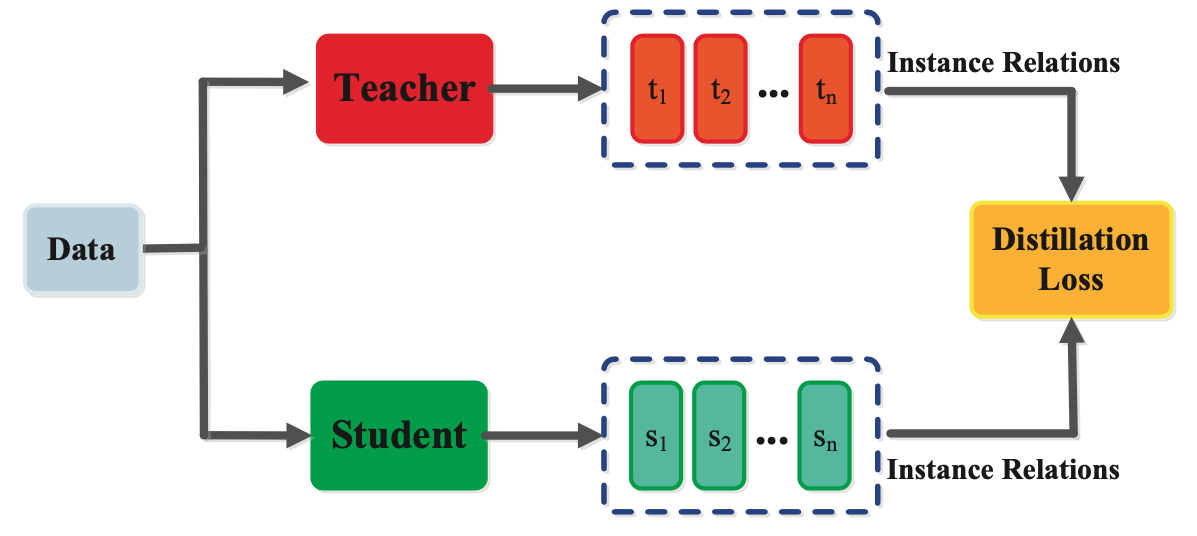
LLM知识蒸馏:让大模型"瘦身"不降智的AI黑科技|DeepSeek为什么会成功? 知识蒸馏是一种将大型模型的知识转移到较小模型的技术,旨在提高小模型的性能,同时降低计算资源的需求。DeepSeek在其模型中广泛应用了这一技术,尤其是在DeepSeek-R1和DeepSeek-V3中。知识蒸馏(Knowledge Distillation)正在掀起大型语言模型的效率革命!这项技术通过"师生传承"的方式,将百亿参数大模型的智慧浓缩到十分之一大小的模型中,在保持90%以上性能的同时,推理速度提升5-10倍。知识蒸馏是一种模型压缩技术,旨在将大型复杂模型(教师模型)所学到的知识转移到较小的模型(学生模型)中,以便于在资源受限的环境中进行有效部署。以下是关于知识蒸馏的基本原理和示意图的详细信息。DeepSeek-R1:该模型通过强化学习和知识蒸馏的结合,显著提升了推理能力。DeepSeek-R1的蒸馏版本包括多个参数规模的模型(如1.5B、32B等),这些模型在数学、编程和自然语言处理等任务上表现优异,且运行成本低。DeepSeek-V3:在DeepSeek-V3中,知识蒸馏被用来将DeepSeek-R1的推理能力集成到更大的模型中,进一步提升了其在知识问答、代码生成和数学能力等领域的表现!知识蒸馏的基本原理知识蒸馏的核心思想是通过教师模型的输出概率分布(软标签)来指导学生模型的训练。这种方法不仅仅是让学生模型模仿教师模型的最终决策(硬标签),而是让学生模型学习教师模型对每个类别的置信度分布,从而更全面地捕捉教师模型的知识。知识蒸馏的步骤训练教师模型:首先使用大量数据训练一个性能优越的教师模型。生成软标签:利用训练好的教师模型对输入数据进行预测,得到每个类别的概率分布,这些概率分布被称为软标签。训练学生模型:使用软标签作为目标,训练一个较小的学生模型,使其输出尽量接近教师模型的软标签。优化过程:通过最小化学生模型输出与软标签之间的交叉熵损失来优化学生模型的参数。示意图在知识蒸馏的示意图中,通常会展示以下几个关键元素:教师模型:一个复杂的深度学习模型,负责生成软标签。学生模型:一个较小的模型,学习教师模型的知识。软标签:教师模型输出的概率分布,包含了对各个类别的置信度信息。损失函数:用于衡量学生模型输出与软标签之间的差异,通常使用交叉熵损失。这种示意图可以帮助理解知识蒸馏的流程和各个组件之间的关系。应用场景知识蒸馏广泛应用于各种领域,包括图像分类、自然语言处理和语音识别等,尤其是在需要将大型模型部署到资源有限的设备(如移动设备和嵌入式系统)时,知识蒸馏显得尤为重要。通过知识蒸馏,开发者能够在保持模型性能的同时,显著减少模型的大小和计算需求,从而实现更高效的应用。一、蒸馏核心技术解析1. 软标签教学法传统训练使用硬标签(如"分类A"),而蒸馏采用教师模型输出的概率分布:# 教师模型输出示例 [0.05, 0.85, 0.10] vs 硬标签[0,1,0]学生模型通过KL散度损失函数学习这种"模糊正确"的决策边界,比单纯记忆标签获得更强泛化能力。2. 中间层知识迁移除了最终输出,先进方法还提取教师模型的隐藏状态:注意力矩阵对齐:让学生模型模仿教师的注意力模式隐藏层映射:通过适配器转换不同维度的特征表示梯度匹配:使学生反向传播路径与教师模型趋同3. 渐进式蒸馏流程graph TD A[原始训练数据] --> B(教师模型推理) B --> C{生成软标签+中间特征} C --> D[学生模型训练] D --> E[动态温度调节] E --> F[最终轻量模型]二、四大实战应用场景移动端部署:将175B参数的GPT-3压缩到1.3B的DistilGPT,手机端实现流畅对话实时系统优化:客服机器人响应时间从800ms降至150ms多模型协同:7B学生模型集成多个领域专家模型的知识持续学习:新模型继承旧模型能力,避免灾难性遗忘三、前沿蒸馏方案对比方法代表模型压缩率性能保留技术特点传统蒸馏DistilBERT40%97%仅输出层蒸馏中间层对齐TinyBERT28%96%嵌入层+注意力矩阵迁移数据增强MetaKD35%98.5%合成训练数据生成结构搜索AutoDistill自定义99%自动寻找最优学生架构四、动手实践指南(PyTorch示例)from transformers import AutoModelForCausalLM, AutoTokenizer import torch # 加载教师模型 teacher = AutoModelForCausalLM.from_pretrained("gpt2-xl") tokenizer = AutoTokenizer.from_pretrained("gpt2-xl") # 初始化学生模型(小型架构) student = AutoModelForCausalLM.from_pretrained("gpt2") # 蒸馏训练循环 for batch in dataloader: with torch.no_grad(): teacher_logits = teacher(**batch).logits student_logits = student(**batch).logits # 计算蒸馏损失 loss = F.kl_div( F.log_softmax(student_logits/T, dim=-1), F.softmax(teacher_logits/T, dim=-1), reduction="batchmean" ) * (T**2) # 结合常规交叉熵损失 loss += 0.5 * F.cross_entropy(student_logits, batch["labels"]) optimizer.zero_grad() loss.backward() optimizer.step(){anote icon="fa-download" href="https://github.com/huggingface/transformers" type="error" content="获取完整代码"/}行业洞察:2024年知识蒸馏市场规模预计达27亿美元,在金融风控、医疗诊断等对实时性要求高的领域,轻量化模型正在快速替代传统大模型。掌握蒸馏技术已成为AI工程师的核心竞争力!