


全球首个支持百万Token上下文的开源大模型来了!**阿里巴巴重磅推出Qwen2.5-1M系列模型,不仅实现7B/14B参数规模下的百万级上下文处理能力,更在长文本任务中超越GPT-4o mini,为开发者提供高性能开源解决方案!本文将详解模型特性、技术亮点与部署教程,助你抢占AI长文本处理技术高地。
一、性能炸裂:双版本碾压式表现
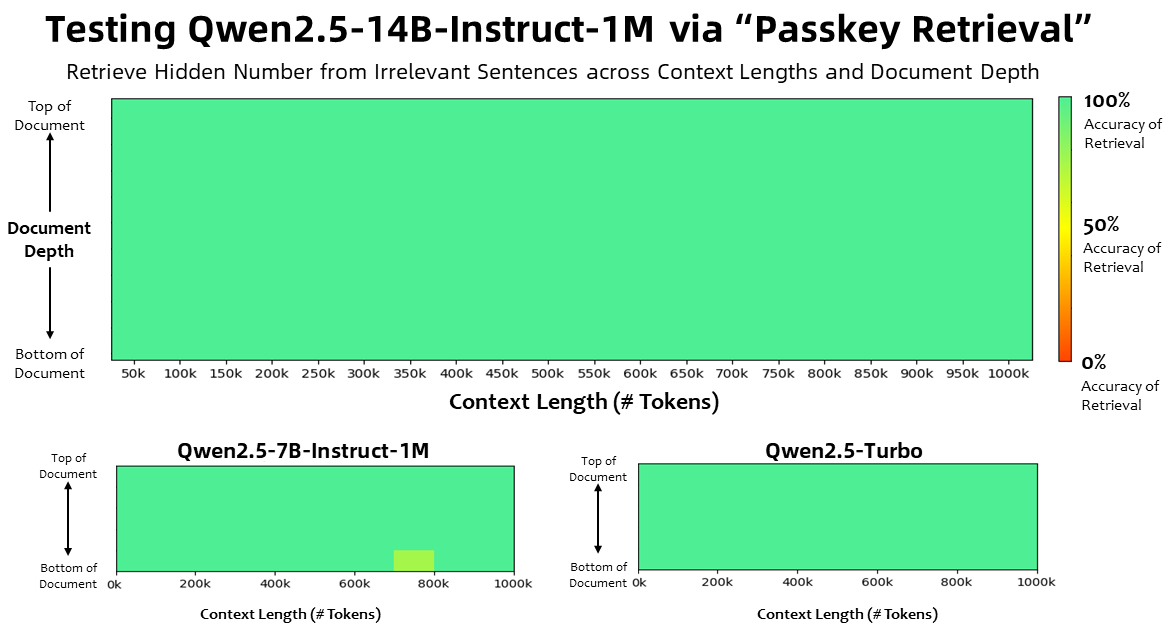
- 百万Token精准检索:在Passkey检索测试中,7B模型百万Token准确率99.8%,14B版本实现零失误
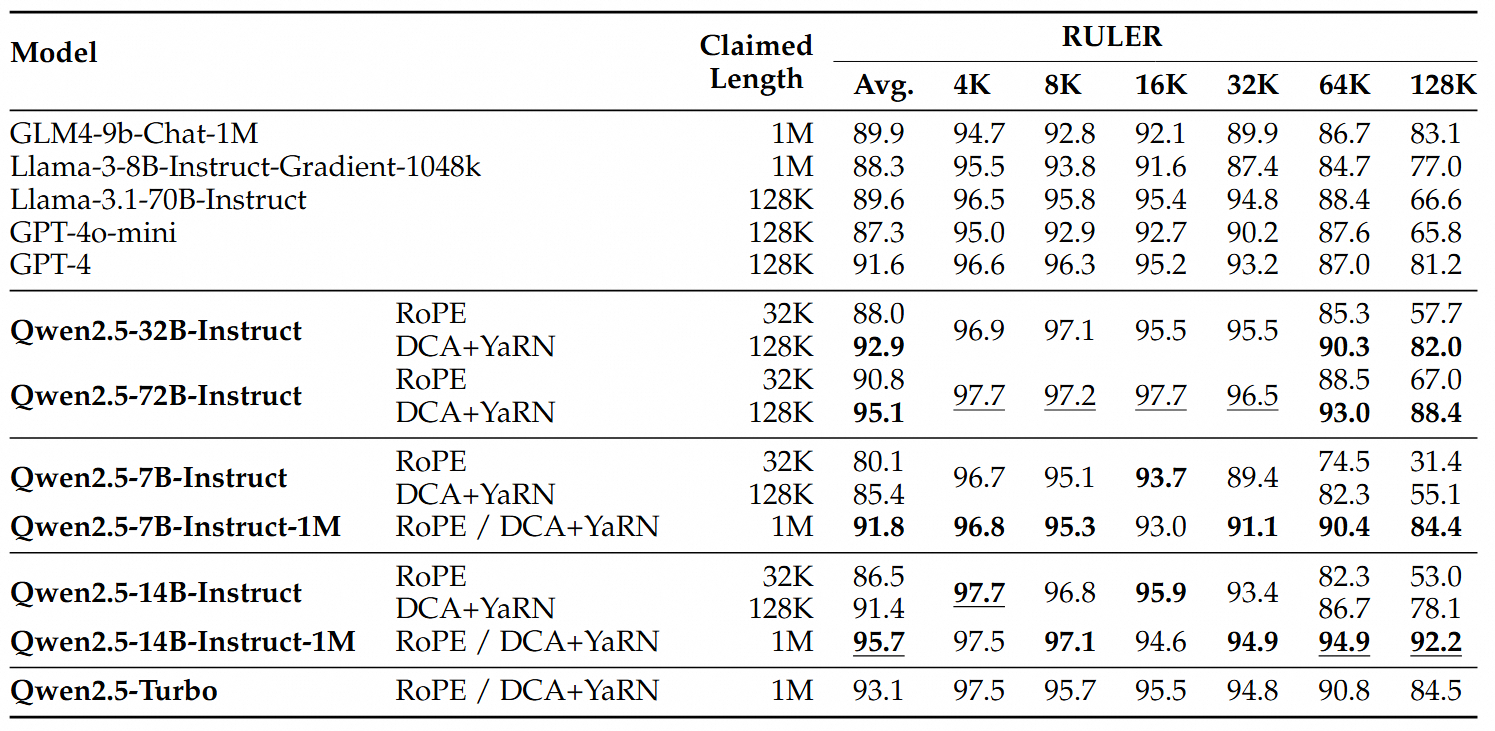
- 长文本理解王者:RULER、LV-Eval等专业测评显示,14B版本比GPT-4o mini平均高12.7%
- 短文本实力在线:MT-Bench得分与128K版本持平,基础能力不打折
二、三大核心技术解析
1. 渐进式长文本训练法
# 四阶段训练策略
1. 预训练阶段:4K→256K上下文扩展 + RoPE基数调至千万级
2. SFT阶段:32K短指令+256K长指令混合训练
3. RL阶段:8K短文本强化学习
4. 最终支持256K上下文2. 双块注意力外推技术(DCA)
- 无需重新训练即可扩展至1M Token
- 相对位置映射优化,解决注意力权重衰减难题
- 32K训练模型实现百万Token零样本外推
3. 智能稀疏注意力加速
# 推理速度提升方案
- MInference稀疏化:预填充速度提升3-7倍
- 动态分块并行:MLP层内存消耗降低96.7%
- 32768 Token分块策略:120GB VRAM轻松处理百万序列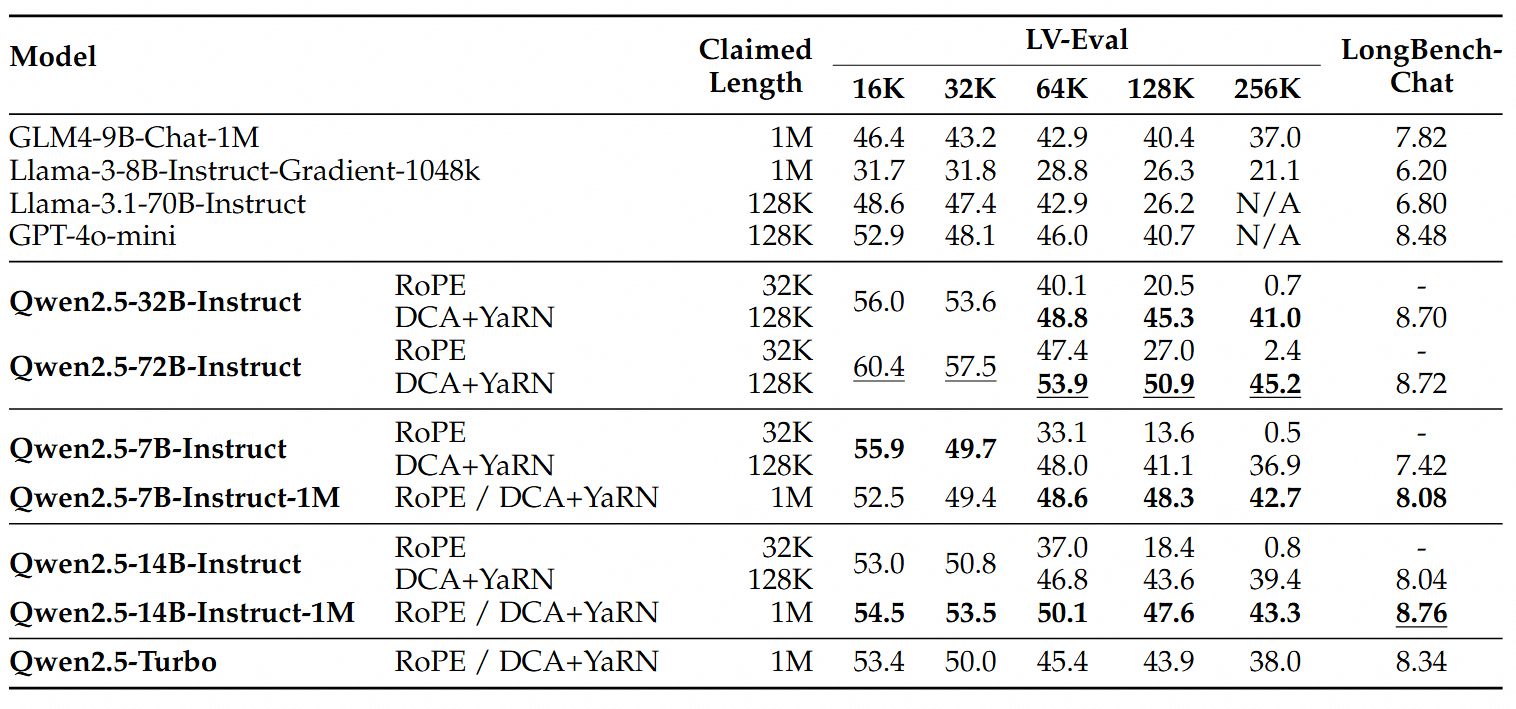
三、手把手部署教程(7B版本)
环境准备
- 硬件要求:4*RTX 4090(120GB显存)
系统配置:
- CUDA 12.1/12.3
- Python 3.9-3.12
- vLLM定制分支
三步快速部署
# 1. 安装依赖
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git
cd vllm && pip install -e . -v
# 2. 启动API服务
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill
# 3. Python调用示例
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1")
response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct-1M",
messages=[{"role":"user", "content":"你的百万Token长文本..."}]
)四、开发者生态支持
- 开源全家桶:完整技术文档+训练框架+微调指南
- 云端体验入口:HuggingFace | ModelScope
- 企业级应用:支持PDF解析、多模态处理的Qwen-Agent框架
重要提示:模型部署需要专业技术支持,建议联系阿里云专家团队获取定制方案!
评论 (0)